Data modeling may start during Benchling implementation, but oftentimes as science (inevitably) changes, tweaks to schema setup and connections change. We put together a resource to guide you through some of the major themes involved in Data Modeling & Discovery to better prepare your teams for these conversations.
Our Data Model & Discovery Best Practice Guide (or BPG for the cool kids) covers:
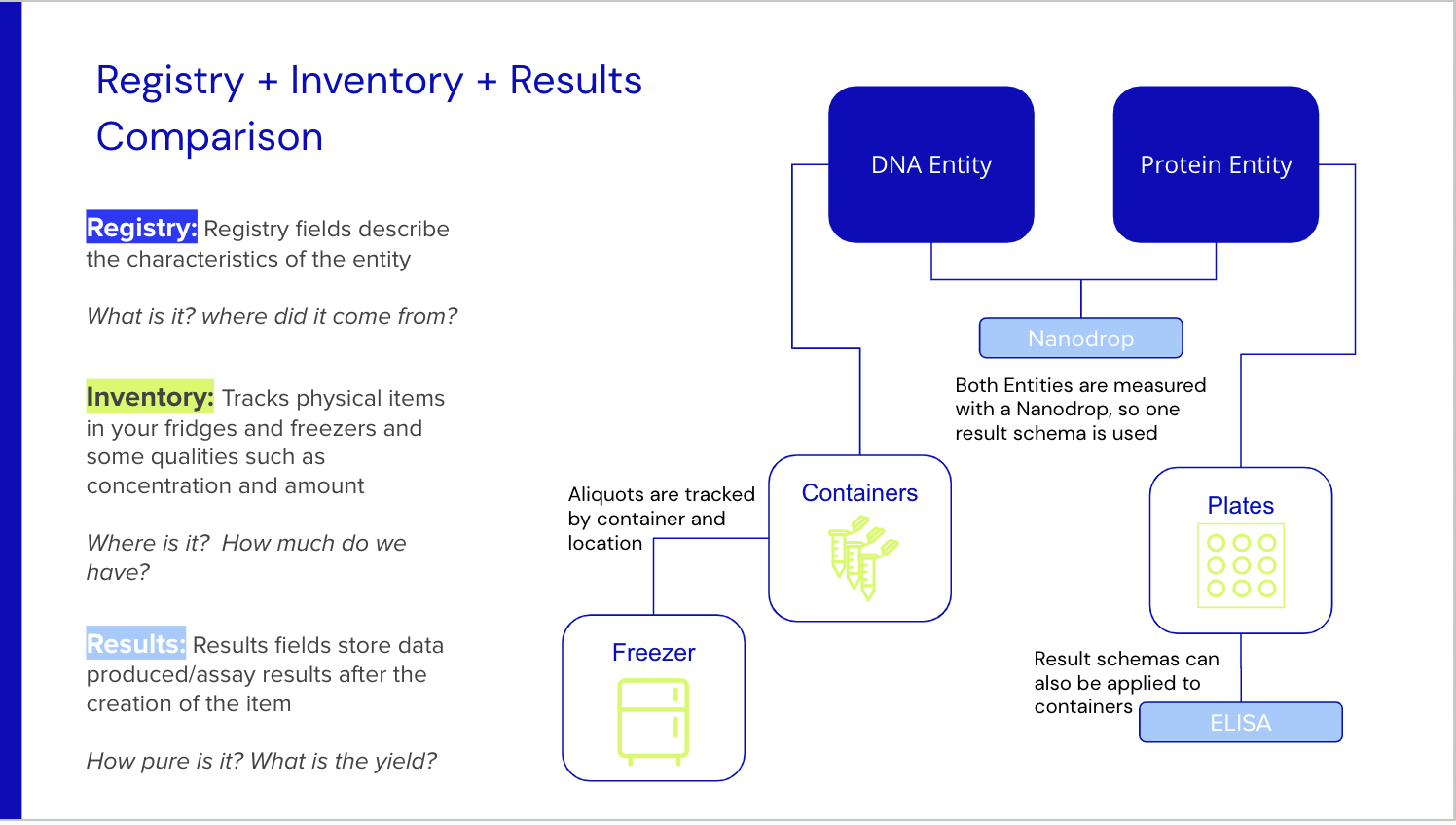
- Registry + Inventory + Results Comparison - Registry, Results, and Inventory capture distinct data types. We outline those differences in the slide previewed below
- Comparing types of Entity Relationships - Entity relationships create links between cataloged samples in your Registry and pass information between them. Choose the appropriate link type for the information you’re hoping share
- Best Practices for Handling Data Model Complexity - Balance the need for an overly-intricate data model with ease of use. There’s no value in having an ornate 50-schema setup if nobody can figure out how to use it
- Best Practices for using Child Entities - Parent Links allow you to track a child entity as a derivative of a parent entity--use them if you want to repeatedly create samples from an entity
- Best Practices for Naming Strategies and Registry IDs - Consider what information your lab uses to identify unique samples and leverage naming templates and Registry IDs to create consistency and clarity in your sample management
Full BPG attached below!
And be sure to join the conversation to let us know how your data modeling discussions are going, where you might be getting stuck or key lessons you’ve learned 🤓